Mysteries of the Deep 🤿: Role of Intermediate Representations in Out-of-Distribution Detection
3Monash University 4Naval Group
NeurIPS 2025
Abstract
Out-of-distribution (OOD) detection is essential for reliably deploying machine learning models in the wild. Yet, most methods treat large pre-trained models as monolithic encoders and rely solely on their final-layer representations for detection. We challenge this wisdom. We reveal the intermediate layers of pre-trained models, shaped by residual connections that subtly transform input projections, can encode surprisingly rich and diverse signals for detecting distributional shifts. Importantly, to exploit latent representation diversity across layers, we introduce an entropy-based criterion to automatically identify layers offering the most complementary information in a training-free setting—without access to OOD data. We show that selectively incorporating these intermediate representations can increase the accuracy of OOD detection by up to 10% in far-OOD and over 7% in near-OOD benchmarks compared to state-of-the-art training-free methods across various model architectures and training objectives.
Why Does This Effect Occur in CLIP?
Our analysis reveals that models like CLIP are uniquely suited for multi-layer fusion. They exhibit two key properties:
- High Inter-Layer Diversity: As shown by Singular Vector Canonical Correlation Analysis (SVCCA), CLIP layers transform representations progressively. There is low similarity between distant layers, meaning each layer provides unique, non-redundant information.
- Prediction Consistency: Despite this diversity, CLIP models show stable prediction behavior across their depth. This means the intermediate layers provide coherent signals that don't conflict with each other, making them ideal for aggregation.
In contrast, supervised and some self-supervised models show high redundancy or abrupt, unstable shifts between layers, which makes fusing their representations less effective.
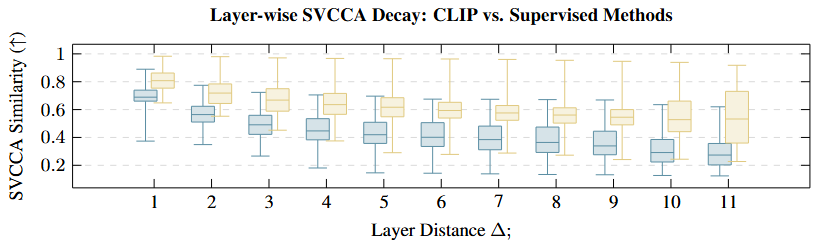
Figure 3 from the paper: Layer-wise SVCCA similarity decay. CLIP models (blue) show faster decay, indicating higher diversity compared to supervised models (yellow).
Our Method: Entropy-Based Layer Selection

Figure 5 from the paper: Overview of our proposed method.
We introduce a training-free extension of Maximum Concept Matching (MCM). Instead of relying on just the final layer, our method intelligently selects and fuses the most informative intermediate layers.
- Fuse Scores: We first calculate OOD scores (using MCM) for various combinations of layers.
- Entropy-Based Selection: We evaluate each combination by computing the entropy of its score distribution on unlabeled in-distribution data. A low-entropy distribution indicates confident, concentrated scores, which is a strong proxy for good ID/OOD separability.
- Select Optimal Layers: The layer combination that minimizes this entropy is chosen as the optimal one for OOD detection.
This entire process is training-free, requires no OOD data for selection, and remains architecture-agnostic for models like CLIP.
How Much Do Intermediate Layers Improve OOD Detection?
Our method does not replace existing OOD techniques—it strengthens them. By integrating the diverse semantic cues present in intermediate layers, we consistently reduce the false positive rate (FPR@95) across several competitive baselines.
Classical OOD Benchmarks with CLIP (ViT-B/16)
The charts illustrate that intermediate-layer fusion provides a significant and universal boost, improving classical OOD detectors like MCM, GL-MCM, and SeTAR.
Intermediate layers consistently lower FPR@95 across datasets. Their complementary representations allow detectors to avoid spurious high-confidence ID activations, especially in ambiguous or complex OOD scenes.
Plug-and-Play for Others CLIP-Backbone Methods
Our approach also enhances prompt-based vision-language techniques such as NegLabel and CSP.
By leveraging intermediate representations, we achieve further reductions in FPR@95, demonstrating that the benefits of our method extend beyond traditional architectures to modern vision-language models.
Interactive Explorer: Fusing Layer Representations
Experiment with different layer combinations to see how fusing intermediate representations via Maximum Concept Matching (MCM) impacts OOD detection performance.
Understanding the Results: Entropy vs. FPR
A key metric we use is FPR@95, which stands for the False Positive Rate when the True Positive Rate is at 95%. A lower FPR@95 indicates better OOD detection performance.
Our core finding is the strong positive correlation between the entropy of a layer combination's scores and its resulting FPR@95.
- Good Selections (Low Entropy): Layer combinations that produce low-entropy (confident and sharp) score distributions for in-distribution data consistently yield lower FPR and better OOD performance.
- Bad Selections (High Entropy): Combinations with high-entropy (uncertain and flat) score distributions perform poorly, often no better than the baseline.
This relationship validates our use of entropy as an effective, unsupervised criterion for selecting the best layers for OOD detection.
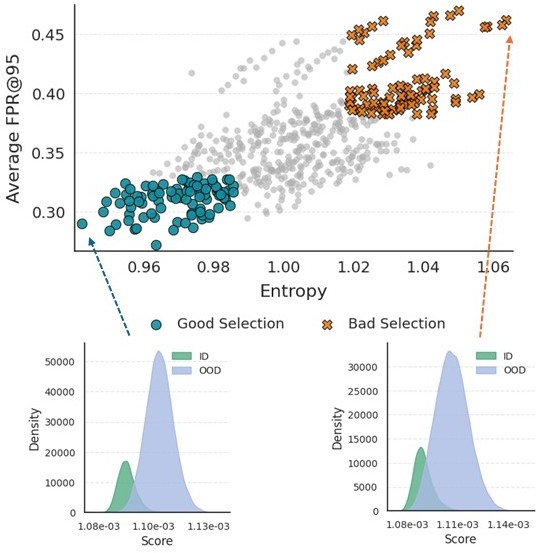
Figure G.11 from the paper: A clear correlation between lower entropy and lower FPR@95.
What Do Different Layers Learn?
Not all layers are created equal. Our analysis shows a clear stratification of semantic concepts across the depth of the network. Early layers specialize in low-level features, while deeper layers capture more complex, high-level concepts. This confirms that to get a complete picture for OOD detection, we need to draw from the diverse specializations of multiple layers.

Figure F.10 from the paper: Low-level concepts like Colors and Textures peak in early layers, while high-level concepts like Objects and Activities emerge in deeper layers.
Why Do Intermediate Layers Help? (Qualitative View)
Beyond numbers, the heatmaps reveal how intermediate layers behave differently from the last layer. On out-of-distribution images, the final layer often places spurious focus on regions that resemble an in-distribution label (red), which can trigger overconfident mistakes. In contrast, a fusion of intermediate layers down-weights these ID-biased regions and amplifies OOD-sensitive evidence (blue), effectively “banishing” the misleading ID signal.

Qualitative comparison of attention maps on OOD examples. Red highlights regions used to support an in-distribution prediction, while Blue highlights evidence for the OOD label. Intermediate layers suppress ID-focused regions and better localize the truly OOD content, explaining their superior detection performance.
Citation
@inproceedings{meza2025mysteries,
title = {Mysteries of the Deep: Role of Intermediate Representations in Out-of-Distribution Detection},
author = {Meza De la Jara, Ignacio and Rodriguez-Opazo, Cristian and Teney, Damien and Ranasinghe, Damith and Abbasnejad, Ehsan},
booktitle = {Advances in Neural Information Processing Systems},
year = {2025}
}